Author:

Graph databases are a type of databases that use a graphical model to organize and present data. In this type of database, data is organized into nodes and edges between nodes. This model is used for efficiently representing and resolving relationships between different entities.
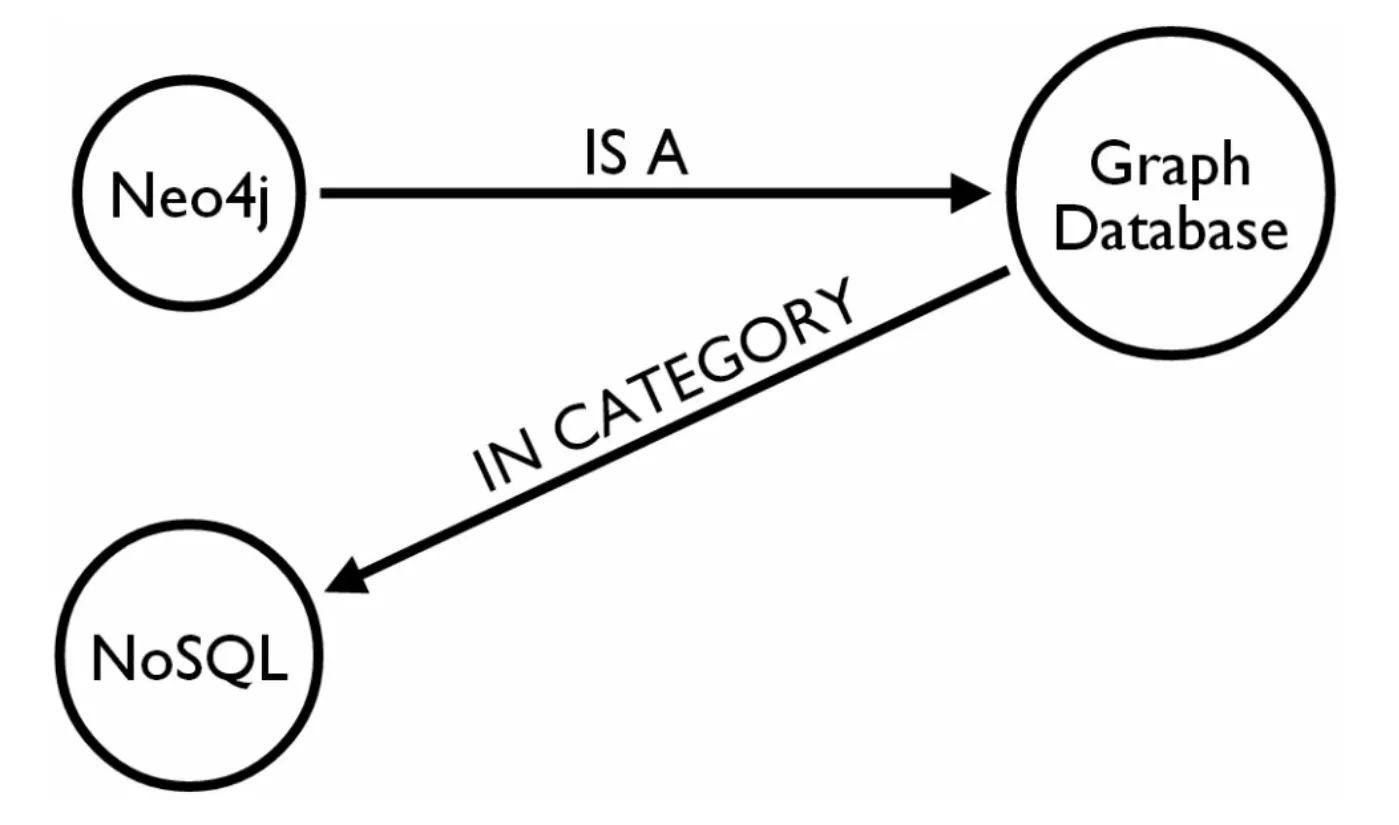
Graph databases are one of the types of NoSQL (Not Only SQL) databases. NoSQL databases are a diverse group of databases that provide alternatives to traditional relational databases. These systems are designed to handle large amounts of data.
Traditional relational databases use a tabular data structure and SQL (Structured Query Language) for queries. On the other hand, NoSQL databases offer different data models and approaches to data handling.
Graph databases are a specific type of NoSQL database optimized for working with data that can be best represented as graphs, with entities and relationships among them. This approach is particularly useful in scenarios where relationships between data are crucial, and efficient analysis of these relationships is needed.
As we can see in the image below, Neo4j represents, alongside JanusGraph, Amazon Neptune, OrientDB, ArangoDB, and Microsoft Azure Cosmos DB, one type of graph databases.Neo4j has its official page where you can find everything you are interested in, if you want to explore this database more deeply
The name “Neo4j” comes from the Greek words “neo,” meaning new, and the suffix “4j,” indicating that this is the fourth version of the database. The founders of the Neo4j database are Swedish programmer Emil Eifrem and his team. The first version of Neo4j was launched in 2007.

Neo4j originated from the initiative of Swedish programmer Emil Eifrem. Emil Eifrem and his team founded a company called Neo Technology to develop a graph database that would be powerful in handling data connected by relationships.
The idea stemmed from the need for efficient data management where relationships between entities are crucial, such as in social networks, recommendation systems, network analysis, and similar scenarios.
The first version of the Neo4j database was launched in 2007. Since then, Neo4j has gone through various versions, improvements, and expansions of functionality. Today, Neo4j is widely used in various industries and applications where the analysis of relationships among data is paramount.
Neo4j is a NoSQL, native graph database open-source software that supports ACID transactions (the latest available version is 4.3). ACID transactions are a set of principles designed to ensure consistency, integrity, and durability of data during transaction execution in a database. The term “ACID” is an acronym for the following concepts:
Principle: A transaction is executed entirely or not executed at all.
Money transfer between bank accounts. If funds cannot be transferred from
one account to another (e.g., due to insufficient funds), the transaction is rolled back, and no changes are applied.
Principle: The database transitions from one consistent state to another.
If you have a database that stores data about students, a consistency rule may
require that each student must have a valid student ID. If a transaction attempts to add a
student without a student ID, that transaction will not succeed.
Principle: Transactions are executed independently of each other.
If two transactions simultaneously read and modify the same data,
isolation ensures that the changes of one transaction will not be visible to the other until the first transaction completes.
Principle: Changes become permanent after the successful completion of a transaction.
When you make a purchase online, once you complete the transaction (pay for the product),
that information is permanently stored in the database to persist even after the connection is lost or the browser is closed.
Neo4j is primarily implemented in the Java programming language and, to a lesser extent, in Scala. As open-source software, the source code is available on a git repository. There are two versions, Community Edition and Enterprise Edition, with the Enterprise version having advanced features like data backup, detailed system monitoring, etc., but it includes some components that are not open source and requires a license. Regarding the data model, Neo4j implements a labeled property graph model and is a native graph database in the truest sense.

The details that make Neo4j a widely-used graph database are:
However, like any technology, Neo4j also has certain weaknesses, as stated in: vertical scalability (data resides on a single server), i.e., no support for horizontal scalability, there is an upper limit on the size of the database (tens of billions of nodes, properties, and relationships in one graph), and there is no data-level security or explicit data encryption support. This means that an application using the Neo4j graph database must handle this aspect if data encryption is needed.

Cypher is Neo4j’s graph query language that lets you retrieve data from the graph. It is like SQL for graphs, and was inspired by SQL so it lets you focus on what data you want out of the graph (not how to go get it). It is the easiest graph language to learn by far because of its similarity to other languages, and intuitiveness.
Cypher is Neo4j’s query language for graphs that allows you to retrieve data from a graph. It’s like SQL for graphs, inspired by SQL to focus on the data you want to get from the graph (rather than how to get it). It is by far the easiest language to learn due to its similarity to other languages and intuitiveness.
The development of new programming languages, including a language like Cypher specifically designed for working with graph databases, often arises from the need for efficient handling of certain types of data and queries that traditional languages, such as SQL, do not adequately address. Here are a few reasons why Cypher evolved as a query language for graph databases:
Graph databases use a graph data model, where data is organized into nodes representing entities and relationships connecting those entities. This model is inherently different from the relational data model used in SQL databases, necessitating the development of a language adapted to the specifics of graphs.
Graphs are often used to model complex relationships between entities. Cypher allows the easy and intuitive expression of these relationships in queries, while SQL requires more complex JOIN operations.
Cypher includes pattern matching, crucial for working with graphs. This feature enables easier recognition and extraction of data based on patterns of relationships and nodes.
Cypher is designed to be readable and easy to write. Graphs are frequently used in situations where it’s essential for developers and analysts to create queries easily and understand the data structure.
Graph databases have specific requirements and performance characteristics that often differ from relational databases. Cypher is tailored to these specifics to enable efficient work with graphs.
In conclusion, the development of the Cypher language facilitates working with graph data and contributes to better query efficiency and readability in the context of graph databases like Neo4j.
If SQL were to be used, the query might look like the following:
SELECT name FROM Person
LEFT JOIN Person_Department ON Person.Id = Person_Department.PersonId
LEFT JOIN Department ON Department.Id = Person_Department.DepartmentId
WHERE Department.name = "IT Department"
On the other hand, the same query using Cypher (the language used by Neo4j) would look like this:
MATCH (p:Person)<-[:EMPLOYEE]-(d:Department) WHERE d.name = "IT Department"
RETURN p.name
From the examples, it’s evident how much simpler it is to construct a query using Cypher, and additionally, the query appears more intuitive and is easier to understand.
How to create Node:
CREATE (n:Actor { name:"Tom Hanks",age:44 })
Actor is the Label, n is the variable for new node and {} brackets to add properties to the node
How to Read Properties of a Node:
MATCH (actor:Actor)
WHERE actor.name="Tom Hanks
RETURN actor;
Actor is the Label, actor is the variable for node, WHERE to restrict the result to our criteria, RETURN the properties on the node
<4>Neo4j platformSystem requirements:
1. Neo4j is supported on systems with x86_64 and ARM architectures on physical, virtual and containerized platforms.
2. It is required to have a pre-installed, compatible Java Virtual Machine to run a Neo4j instance.
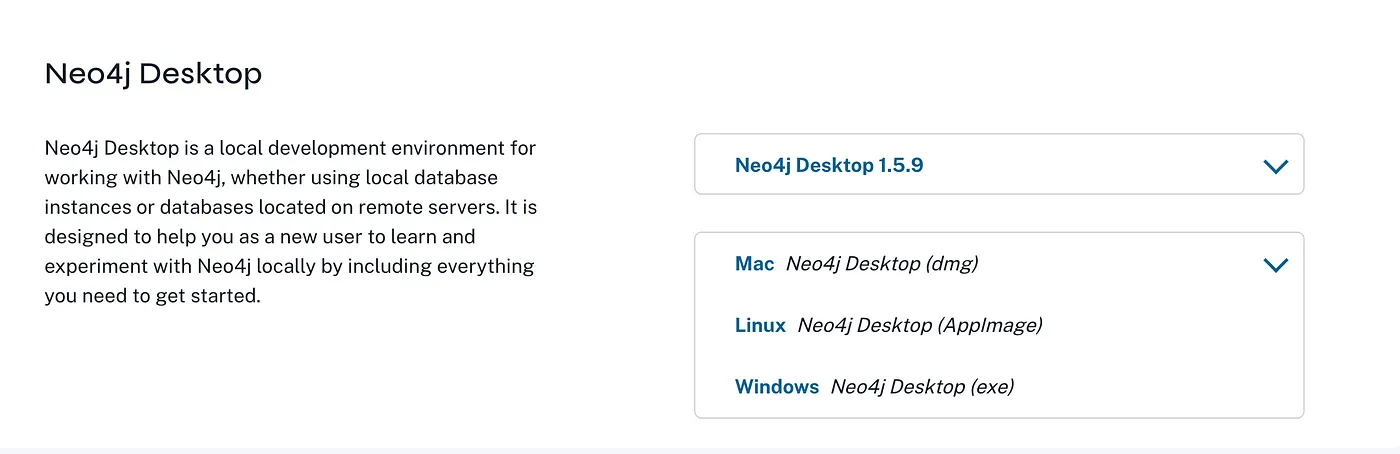
Installation link : https://neo4j.com/deployment-center/#desktop
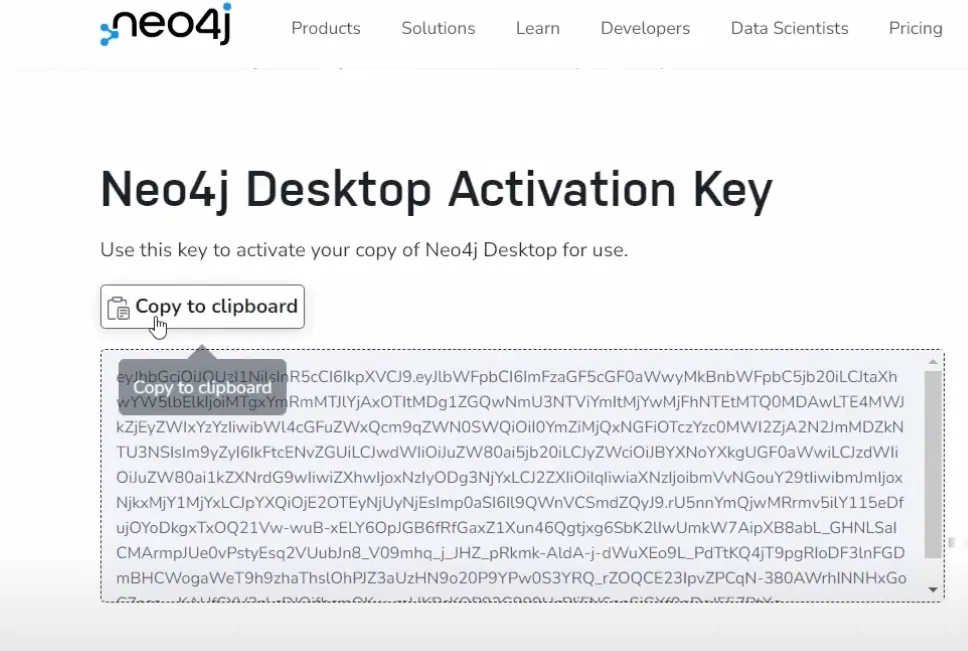
After this step use the key to activate Neo4j Desktop
Run the exe file to start the installation
Choose location
Finish installation
Activate Neo4j Desktop with key
This is the first thing we see after launching the Neo4j Desktop application
Let’s set the name of the project and create a local database
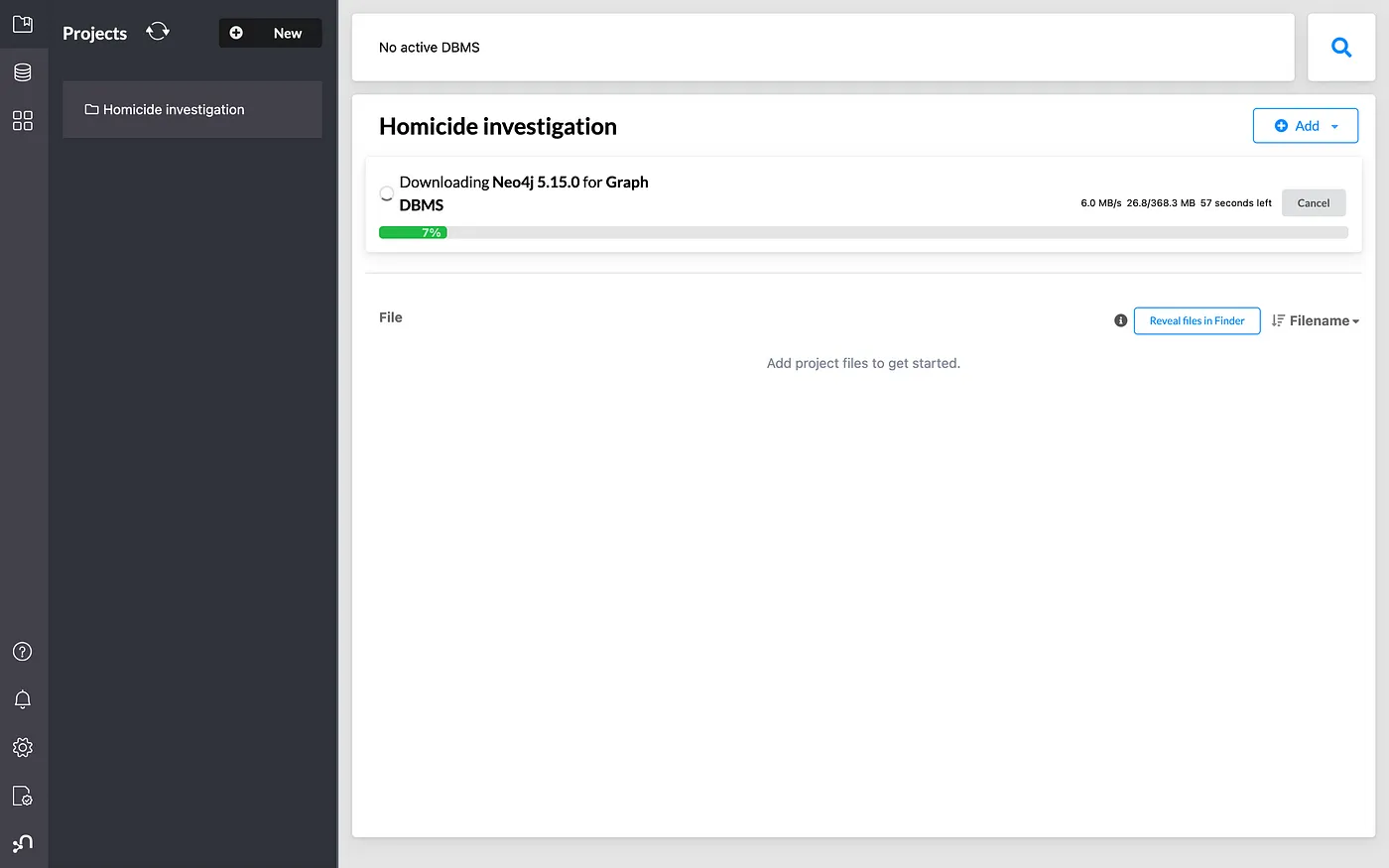
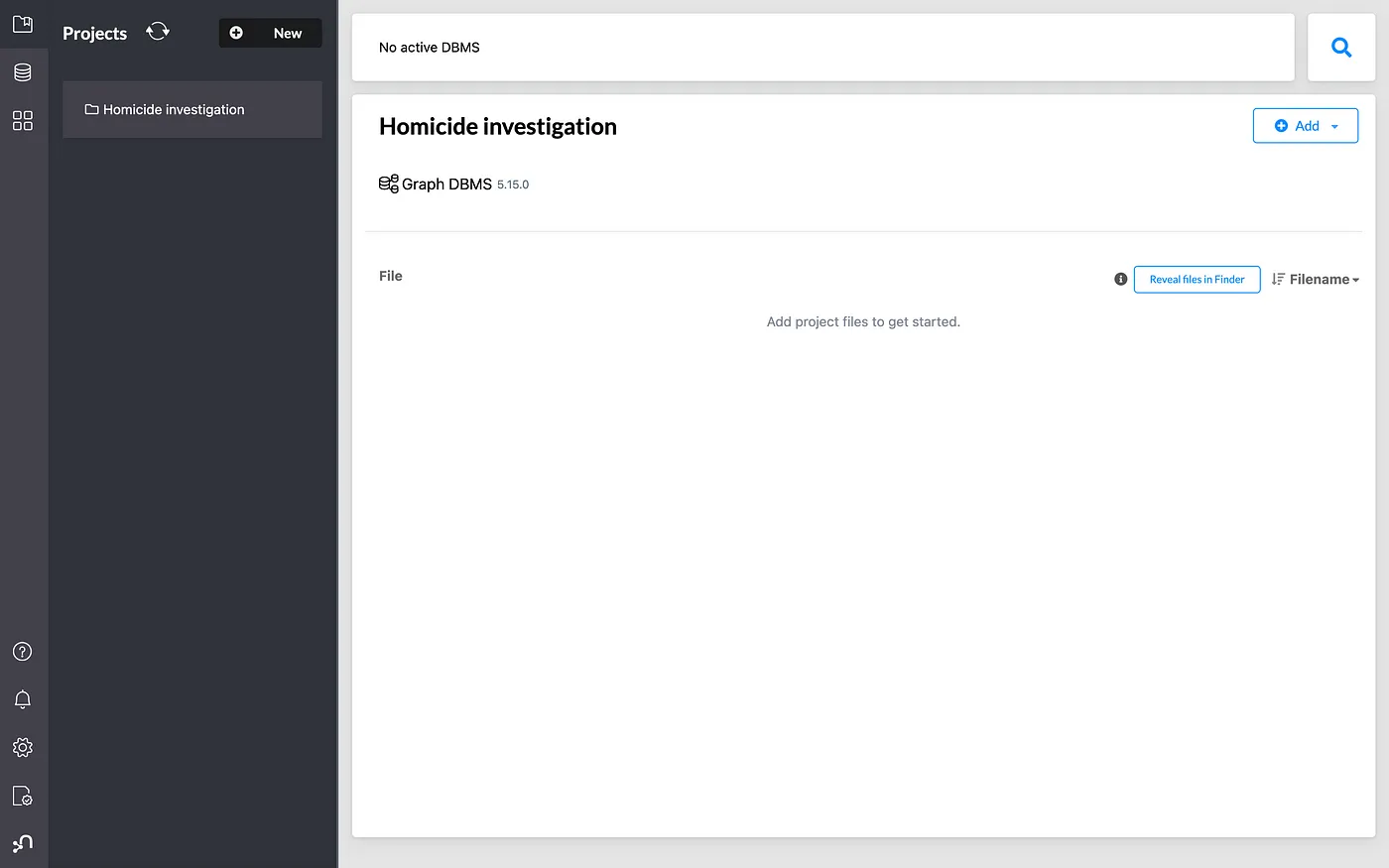
After installation, click on the Start button to launch the project in the Neo4j Browser.
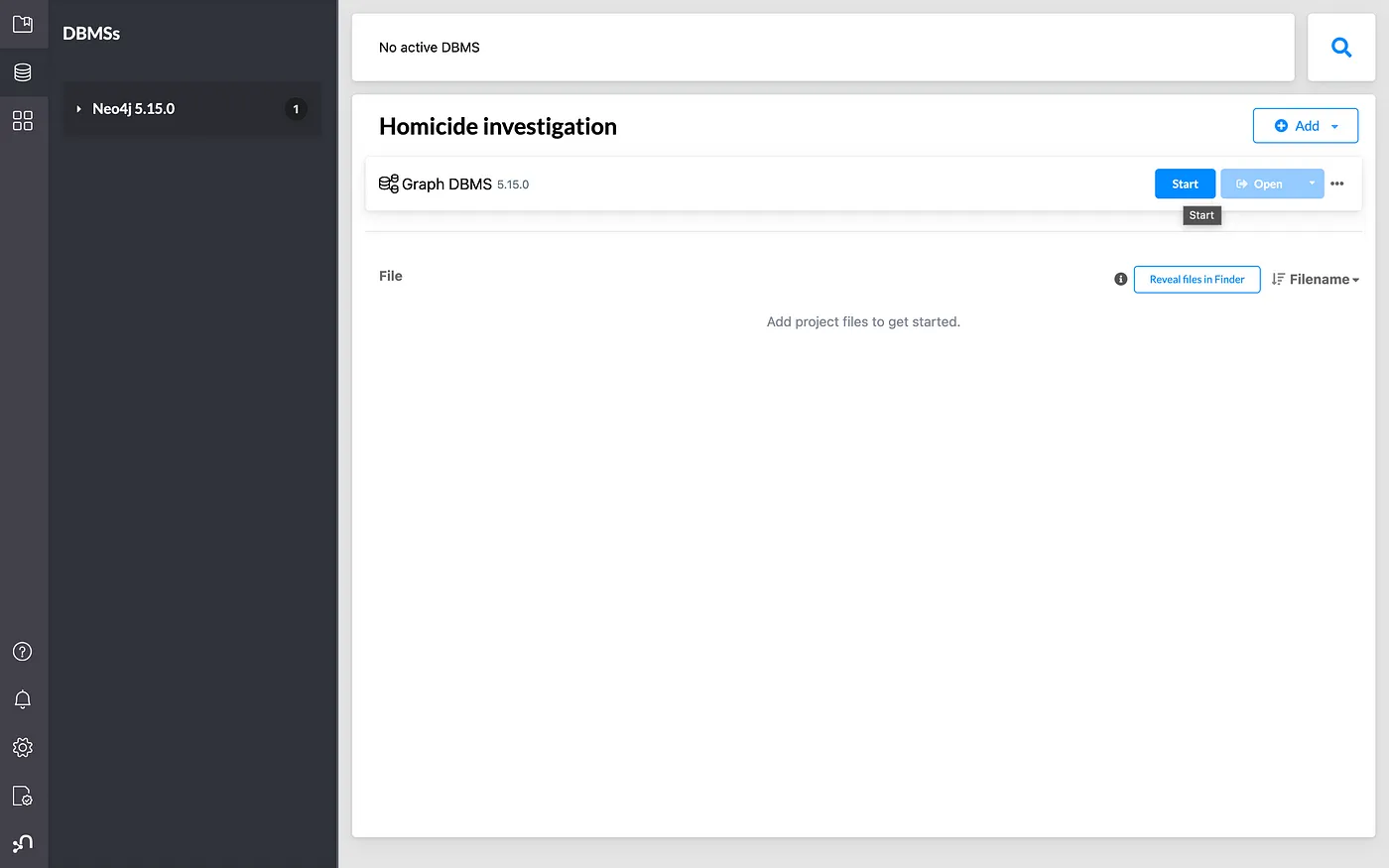
This is what it looks like when we launch the Neo4j Browser.
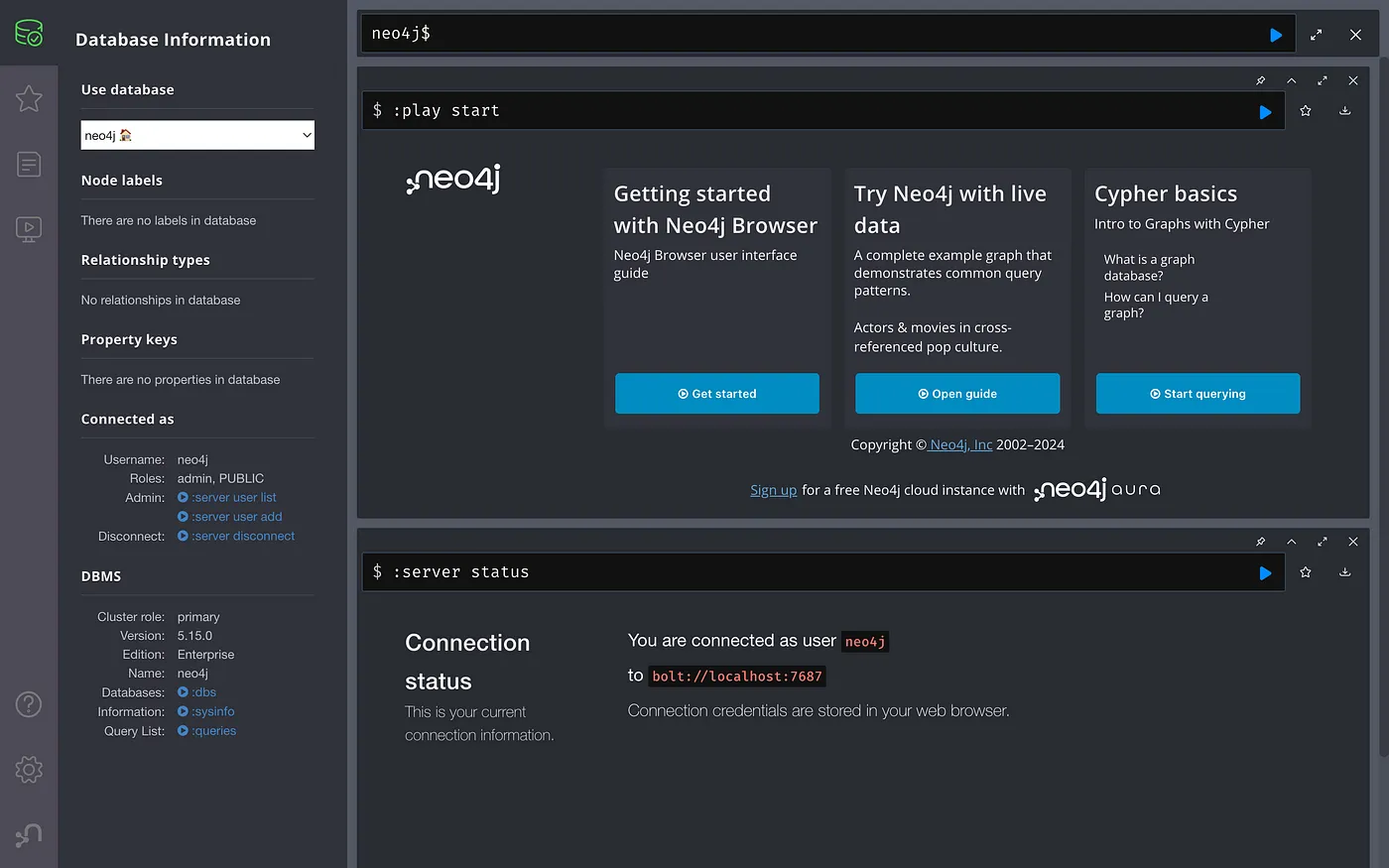
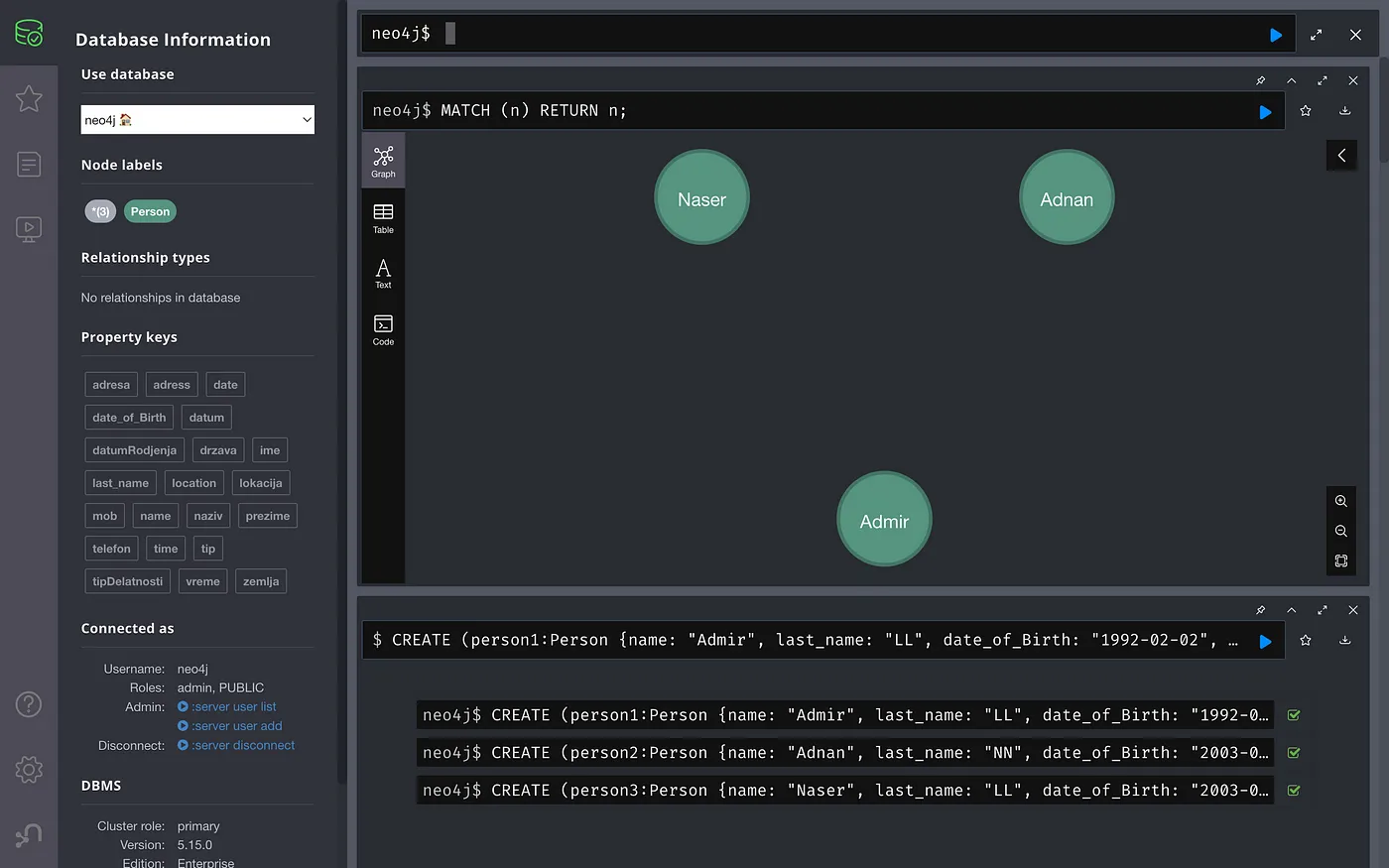
Now let’s enter some data.
// Person one
CREATE (person1:Person {name: "First Name", Last_name: "last name",
Date_of_Birth: "YYYY-MM-DD", adress: "Address", mob: "mob"});
// Person two
CREATE (person2:Person {name: "First Name 2", Last_name: "last name2",
Date_of_Birth: "YYYY-MM-DD", adress: "Address", mob: "mob2"});
// Person three
CREATE (person3:Person {name: "First Name 3", Last_name: "last name3",
Date_of_Birth: "YYYY-MM-DD", adress: "Address", mob: "mob2"});
CREATE — as the name of the clause itself suggests, is used to create nodes and relationships in the database. We can create them individually or define a pattern that will then create all the defined nodes and relationships.
We can edit data:
The update is done at the level of both node and relationship properties, for
this purpose, the SET clause is used. We specify MATCH
MATCH (person:Person {name: "Name"}) SET person.address = "New address"
RETURN person;
We can delete data:
When deleting, there is a difference between deleting a node and a relationship. If we want to delete a node, we will then use the DELETE keyword, and we must be aware that deleting a node with the DELETE keyword is only allowed when it has no connections, meaning the node is not connected to any other node in the graph. How then can we delete a node and, together with it, delete all the relationships going to or from it or both? For such situations, there is a special clause called DETACH, which deletes all relationships associated with that node as well as the node itself. DELETE is used for deleting an object, and for deleting properties, there are several approaches. One approach is to use UPDATE to set some property to null, but if we specifically want to delete a property from a node or relationship, then the REMOVE keyword is used. REMOVE removes a specific property from the structure of the node or object.
MATCH (n)
DETACH DELETE n;
One very important thing, when using CREATE, Neo4j will blindly obey us. This means that when we tell Neo4j to CREATE
If we want to filter part of the results based on some property or the value of a property, then the WHERE clause is used. And WHERE is more or less like SQL. Working with strings is more or less identical to SQL; the problem lies in working with dates (if there are issues, consult the professor).
If we want to write a query that resembles a left/right join in SQL, an example of this would be if we want to find all nodes that are movies and that have at least one actor connected to them, where the query returns the name of that actor. But if there is no connected actor, then only the movie name should be returned. In such a situation, use the optional match.
Cypher supports some basic aggregation functions, count (over any part of the result), distinct, has support for creating arrays (using the COLLECT function, to iterate over a collection, use unwind), sorting (ORDER BY), limiting the number of results, etc.
When we use this command:
We can see the graph with the entities we have entered so far
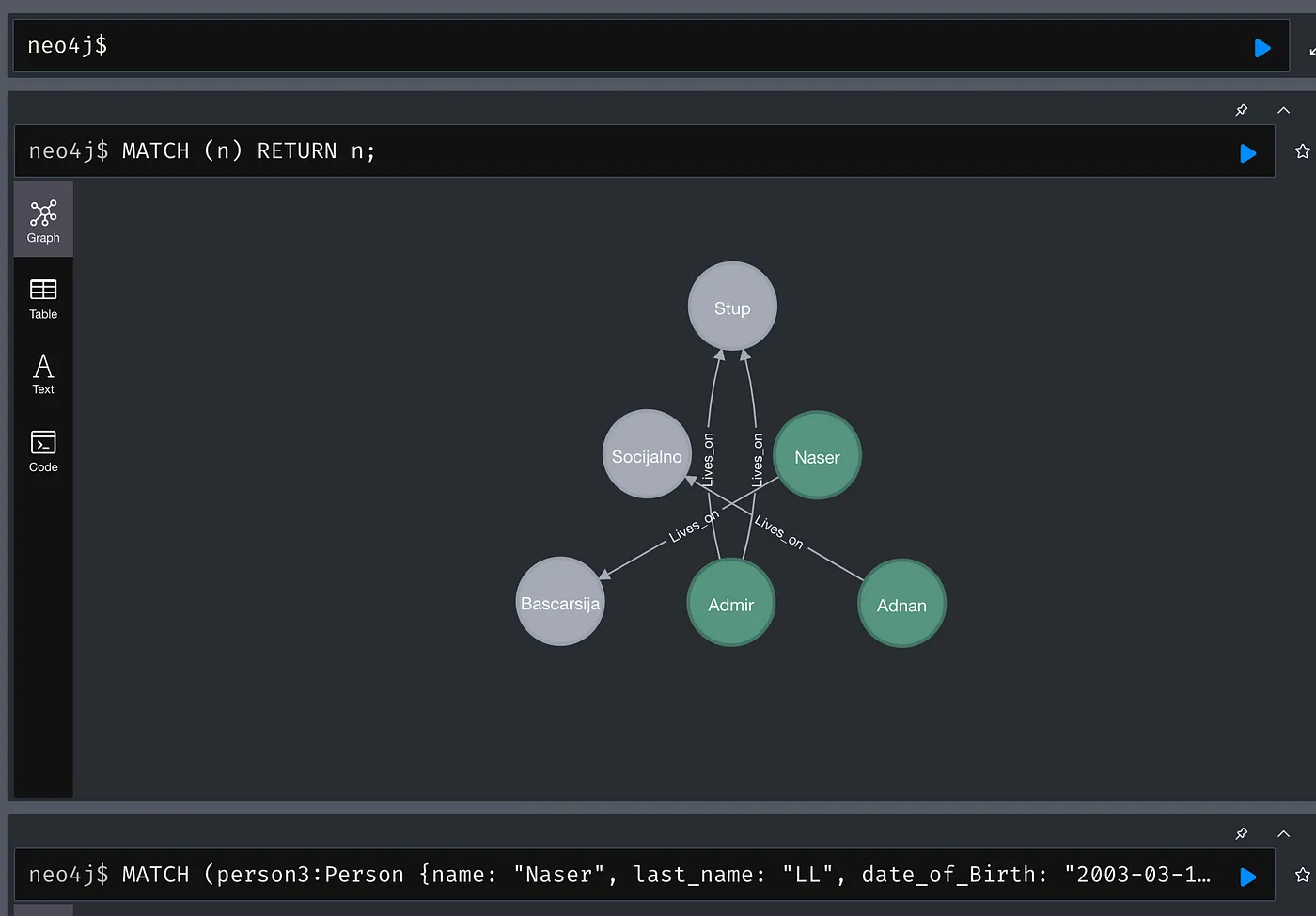
Now we will enter the other entities and the relationships between them
Create “place” entity and add relations with the first entity
CREATE (place:Place {name: "Name of place", adress: "Adress"});
MATCH (person:Person {name: "Name"})
MATCH (place:Place {name: "Stup", address: "Stupska b.b"})
CREATE (place)-[:Lives_on]->(place);
RETURN person, place;
This is what our graph looks like now
We create two entities, “job1” and “job2”. After creating them, we establish relationships with the first entity.
CREATE (job1:Job {name: "Bitcoin trader", address: "Remote", type: "trader"});
CREATE (job2:Job {name: "Waiter", address: "Caffe NN", type: "service industry"});
MATCH (person:Person {name: "Admir"})
MATCH (job:Job {name: "Waiter", address: "Caffe NN", type: "service industry"})
CREATE (person)-[:Work_like]->(job);
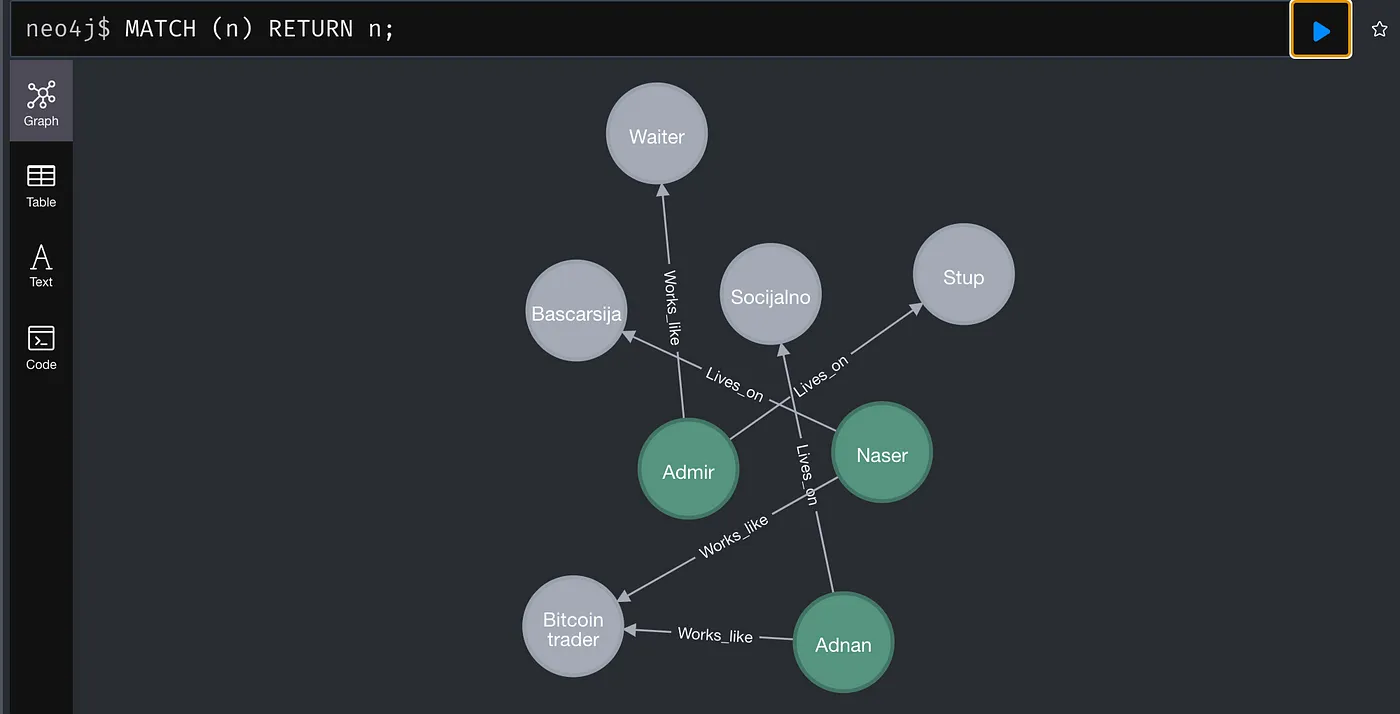
Now we are adding a relationship between the first and last person.
MATCH (person1:Person {name: "Name"})
MATCH (person3:Person {name: "Name"})
CREATE (person1)-[:Brother]->(person3);
We are creating the “Murder” entity
CREATE (murder:Murder {date: "Date", time: "Time", location: "Loaction"});
All three individuals were present at the murder scene simultaneously, where the third person was killed.
MATCH (person1:Person {name: "Name"})
MATCH (person2:Person {name: "Name"})
MATCH (person3:Person {name: "Name"})
MATCH (murder:Murder {location: "location"})
CREATE (person1)-[:IT_WAS_LOCATED_AT]->(murder)
CREATE (person1)-[:IT_WAS_LOCATED_AT]->(murder)
CREATE (person3)-[:IT_WAS_LOCATED_AT]->(murder)
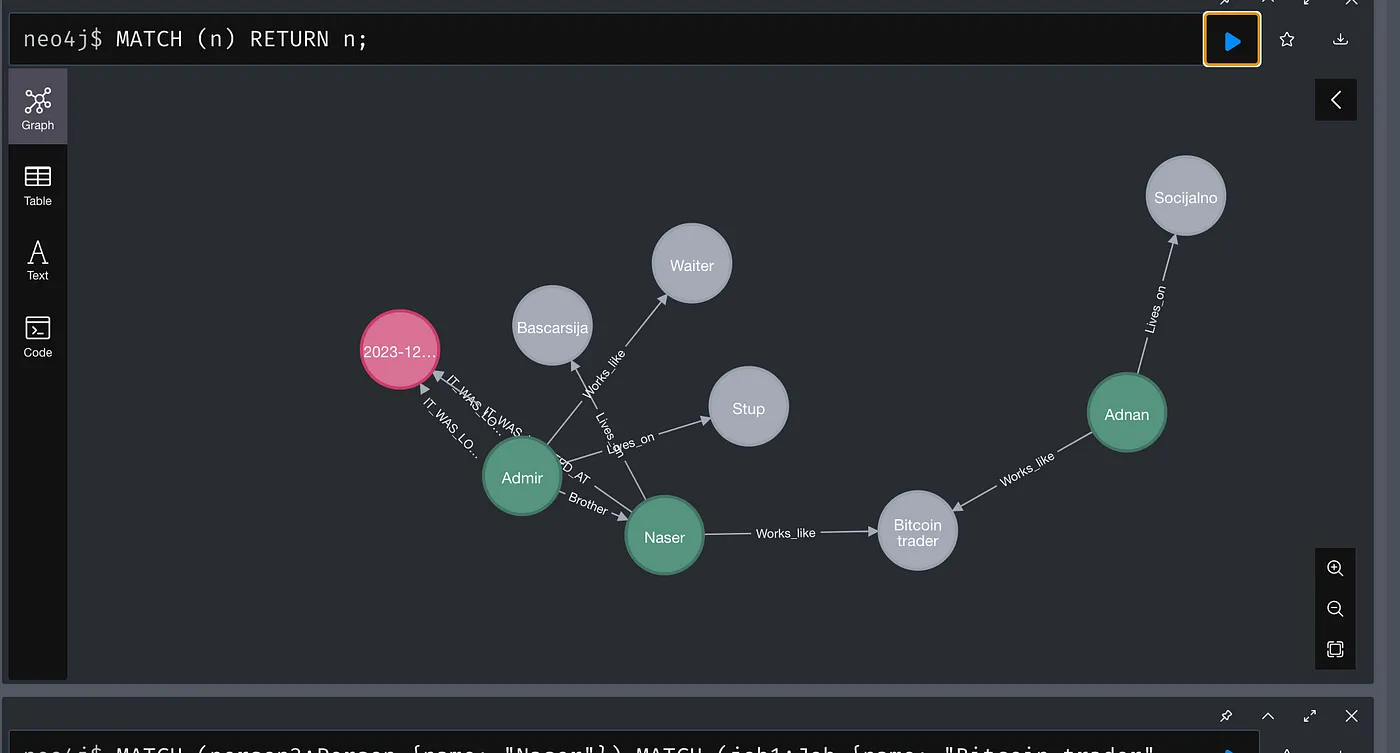

Who the murderer is depends on you; let your imagination run wild and create your own scenario.
Here are a few examples of where Neo4j can be used in applications focusing on social connections:
Applications supporting social networks can use Neo4j to store information about users, their friendships, communities, and interactions. The graph database model provides an efficient way to represent and query such interconnected data.
Neo4j can be utilized to implement recommendation systems. For instance, by analyzing social connections and interactions, an application can suggest new content to users based on the preferences of their friends or similarities in interests.
Applications dealing with social network analysis, sociological relationships, or studying network behavior can leverage Neo4j for data storage and analysis.
In applications focusing on security analysis, Neo4j can be used to track relationships between different entities and detect unusual patterns of behavior.

Neo4j, as a graph database, provides a powerful and efficient tool for modeling and managing data that involves complex relationships. Throughout this blog, we have demonstrated key commands such as CREATE, MATCH, SET, which enable the creation, retrieval, and updating of data. Understanding clauses like OPTIONAL MATCH, RETURN, and WHERE gives us additional flexibility in shaping queries according to specific needs. Additionally, the REMOVE clause allows precise management of node and relationship properties.
Neo4j stands out in situations where relationships between data are crucial, such as social networks, network analysis, or any application where the data structure is graph-based. Its ability to intuitively model and rapidly execute queries makes it a popular choice for scenarios where relationships are of paramount importance.
In conclusion, Neo4j provides a robust framework for working with graph data, facilitating the development of applications that demand a deep understanding of relationships among entities.
Author: